The UCSF Health Problem
We aim to automate specialty-specific chart review, a high provider burden, error-prone process that costs clinicians 15–45 minutes per patient, leading to 6–12 hours of weekly administrative overhead contributing to pajama time. This burden impairs clinic throughput, contributes to burnout, and compromises care quality, especially in specialties like Gastroenterology where fragmented, longitudinal data including scanned outside records are the norm.
Despite advances in interoperability, no existing solutions address the upstream need to synthesize relevant clinical history for decision-making. Our innovation lies in generating real- time, specialty-aware clinical state summaries tailored to how specialists’ reason about patient care in several GI subspecialities.
Our end users are specialty physicians and advanced practice providers managing chronic, complex conditions who need accurate, longitudinal insights to deliver collaborative, high-quality care.
How Might AI Help?
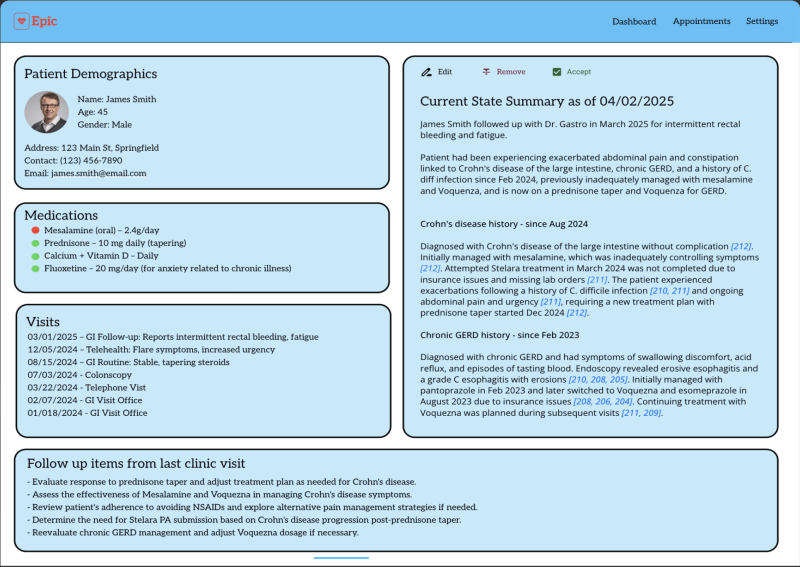
Our AI system analyzes structured and unstructured EHR data—including scanned documents, provider notes, imaging and procedure reports, pathology results, and medication histories—to generate a clinically accurate, specialty-specific “current state” summary with references to original source text, spanning all prior encounters. This enables providers to begin each visit fully informed, without time-intensive manual review with references to sources of information available in line with the summaries. While transformer models have shown promise in summarization, they often produce hallucinations or omit critical context. Our architecture will involve technical collaboration with Acucare AI, a company that addresses these limitations using retrieval-augmented generation, domain-specific knowledge graphs, and specialty-tuned pipelines to ensure high clinical reliability of the outputs.
By automating a task that currently takes clinicians hours, our AI compresses chart review to minutes—improving care efficiency, quality, and clinician well-being.
How Would an End-User Find and Use It?
At first our AI tool will first be deployed as a standalone web application (link provided to authorized users) within UCSF’s secure cloud infrastructure, allowing rapid iteration and clinician feedback. It will generate a structured “current state” summary from EHR data, optimized for specialist workflows and presented in a clean, reviewable interface. A small subset of physicians will have the opportunity to validate, edit, and improve the AI-generated content during this testing phase. Once validated, the tool will be fully integrated into the EHR and surface within the existing pre-charting section—requiring no significant change to current clinical workflows. The AI summary will appear where clinicians already look for relevant patient history, pre-populated and linked to source data for easy verification.
The tool is most valuable just before the visit, replacing hours of manual chart review with an AI- generated, physician-ready summary that can be accepted as-is or modified. Because the AI
output fits seamlessly into current documentation practices, end-users are not required to learn new systems or processes. They simply review the summary, just as they do today the past medical records, only faster, more comprehensively, and with greater confidence in data accuracy.
This approach enables >30% reduction in pajama time and cognitive burden while preserving existing clinical workflows and autonomy.
Example of AI output
What Are the Risks of AI Errors?
The primary risks in most AI solutions include hallucinations (fabricated or unsupported information), omissions (missing key clinical details), and misclassification of clinical relevance—each of which can present risks to clinical decision-making if not addressed and diminished trust in AI outputs.
To mitigate these risks, we are collaborating with Acucare AI, which is developing a hybrid architecture combining large language models (LLMs) with a domain-specific clinical knowledge graph. This approach improves clinical specialty precision and recall, enabling AI outputs to be validated against structured medical knowledge in a measurable and reproducible way.
In addition, we will also conduct rigorous physician-led evaluations to qualitatively assess the accuracy, completeness, and clinical usability of the summaries. These outputs will be benchmarked against off-the-shelf LLMs to quantify improvements in reliability and clinical relevance in our novel hybrid approach.
This rigorous testing and validation framework including quantitative validation using knowledge-grounded AI, and qualitative feedback from domain experts—ensures high-fidelity outputs suitable for clinical deployment. With this approach errors are minimized, identified early, and iterated upon in a controlled environment prior to scale-up.
How Will We Measure Success?
We will evaluate the success of this pilot using three core metrics:
Precision and Recall of Clinical Concepts: We will quantitatively compare the performance of our hybrid Knowledge Graph + LLM pipeline against baseline LLM models alone, assessing the accuracy and completeness of extracted clinical concepts across patient records.
Qualitative Clinical Evaluation: Specialists will assess the completeness, accuracy, and clinical utility of AI-generated summaries for their own patients. This expert review will be captured for each summary through a live evaluation feature (such as a thumbs-up/down button) and ensures alignment with real-world expectations and safety in specialty care.
Time Saved Per Encounter: We will measure reductions in administrative and “pajama time” through pre- and post-intervention analysis. This can be done in an automated fashion by using APeX metadata (amount of time spent in a patient’s chart prior to their visit).
If the pilot fails to demonstrate adequate performance on metrics (1) or (2), we will either explore alternative approaches to improve the technology or halt the program, prioritizing safety, reliability, and clinical value.
Describe Your Qualifications and Commitment
I am a GI physician, IBD specialist, and a data science researcher at UCSF. As a physician I can personally attest to the substantial burden of chart review in my clinical practice. This is particularly a challenge for the IBD patients I see. UCSF is a tertiary care center of excellence, and we get many outside referrals from the greater Northern California area for IBD diagnosis and management. These patient records are frequently fragmented and often in formats that are especially difficult to review (scanned clinical documents of outside faxes, care everywhere data). A tool such as we propose to develop with Acucare AI, with the support of the UCSF AI and AER teams, will be a huge benefit to providers and patients at UCSF.
This work also aligns closely with my research lab’s work on data science methods for EHR data. We have developed and evaluated different computational methods for abstracting and summarizing clinical data, particularly clinical notes. Over the past year I have been working closely with Acucare AI to extend these approaches using advanced AI engineering methods to retrieve and summarize clinical data for clinicians. Acucare AI is led by Ganesh Krishnan and Chandan Kaur, who together bring technical depth in AI/ML, specialty-specific knowledge modeling, healthcare products and 35+ years of experience in product innovation.
I am confident that over a 1-year pilot we will be able to rigorously test our approach and make a go/no-go decision on whether to fully deploy it and scale it across diseases. If selected I will commit at least 15% effort for 1 year towards this project to ensure its success.
Comments
Have you validated accuracy
Have you validated accuracy of the summaries produced by Acucare? It seems like this could be done retrospectively. If it produces really good accurate summaries that clinicians rate as being very helpful (and would truly obviate the need for lots of manual chart review prior to seeing a patient), this could be very impactful.