1. The UCSF Health problem
Large language models (LLMs) have rapidly emerged as powerful tools in clinical medicine, offering advanced capabilities in information retrieval, decision support, and diagnostic reasoning. Many clinicians (including at UCSF) are already using publicly available LLMs (ChatGPT, Claude, OpenEvidence) for clinical queries. Beyond challenges related to security and patient privacy, because the LLM does not interface directly with patient data, clinicians cannot easily obtain fully contextualized, patient-specific responses (taking into account age, past medical history, medications, etc.). The lack of an integrated solution means clinicians must manually enter curated data into an LLM to achieve the best results – a process with significant error risk.
Moreover, ensuring the reliability of AI-generated responses to clinical queries is paramount: mechanisms that ensure transparency of information sources are critical as they allow for physician oversight. Clinical AI tools must provide evidence-backed answers with clear citations to ensure human-in-loop medical decision making. With the rapid adoption of LLMs, UCSF clinicians will soon require an AI tool that delivers trustworthy, patient-tailored evidence within their workflow. OpenEvidence is an AI tool designed and trained specifically to deliver evidence-based and is already used widely in the UCSF and broader medical community (reportedly used by over 20% of U.S. doctors).
2. How might AI help?
We see an opportunity to integrate OpenEvidence within UCSF’s clinical environment to enhance its utility. We propose a light integration via a SMART on FHIR application that can securely access and extract relevant structured patient data (e.g., demographics, active medications, comorbidities, allergies) from the EHR. By automatically incorporating such context, an in-EHR OpenEvidence tool could deliver more precise and personalized real-time clinical support, reducing clinician burden and minimizing the risk of context omissions. For example, when a hospitalist asks a question (such as, “What is the optimal anticoagulation strategy for a patient with a DVT?”), the system would access structured data like the patient’s demographics (age, sex), active problem list (such as history of GI bleed), current medications, lab results, and other key context via the FHIR API. Using these details, the AI can interpret the question in light of the specific patient (e.g. “78-year-old female with atrial fibrillation, chronic kidney disease stage 3, on metformin…”). This context inclusion helps the LLM formulate an answer that is relevant to the individual patient, rather than a one-size-fits-all response and reduces reliance on the clinician to know every covariate that would change or contextualize the specific question at hand.
For this pilot, the app will pull key structured fields (patient demographics, medication list, allergy list, active diagnoses, and possibly recent vital signs or lab values) but not free-text notes, to limit complexity. With these inputs, OpenEvidence’s backend LLM can retrieve matching evidence (guidelines, clinical trial data, etc.) and generate an evidence-based answer. Crucially, the output will include transparent citations. By having the specific patient context, the AI can filter out irrelevant information and highlight applicable evidence. We believe this integration would produce outputs that are highly specific and grounded in evidence, closing the gap between raw EHR data and medical knowledge at the bedside.
3. How would an end-user find and use it?
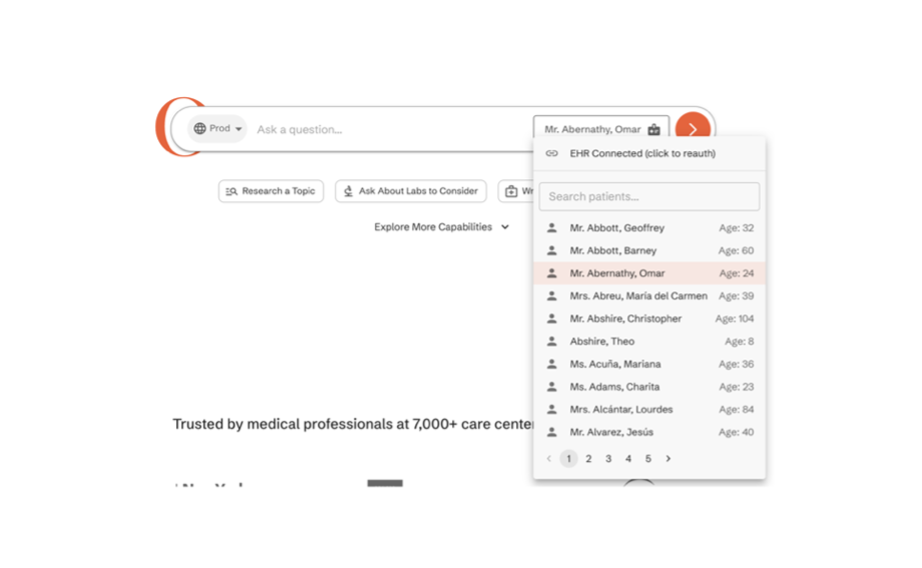
Our primary end-users during this pilot will be inpatient hospitalists – specifically those on the UCSF Goldman(attending only service) service and the Medicine Teaching service (attending physicians and residents on the general medicine wards). We plan to deploy OpenEvidence as an embedded SMART on FHIR app, eitherwithin Epic or externally depending on UCSF AI teams recommendations (The OpenEvidence engineering team are willing to facilitate either). The interface would include a list of all patients within a user’s service list and allow selection of one patient at a time. Once launched, the user interface would be straightforward and familiar. The clinician is presented with a text input field labeled something like “Ask a clinical question about this patient.” They might type, for instance, “Does this patient’s diabetes and heart failure change the target hemoglobin for transfusion?” and hit submit (Figure 1; Section 4 below). The answer would consist of a few paragraphs of explanation, written in concise clinical language, and will include small reference superscripts or bracketed numbers corresponding to citations. The UI will prominently show these citations (e.g. a sidebar or footnote list of reference titles), as well as the ability to mark accuracy of both answer and provided citations.
4. Concept figure

5. What are the risks of AI errors?
No AI is perfect – especially in high-stakes clinical settings – so we have identified several risks and failure modes, along with mitigation strategies for each:
- Overfitting to unique patient context: Evidence from the published literature is limited and often much simpler than highly complex clinical practice. If fed full patient chart information, the LLM might give an answer that overemphasizes those idiosyncratic details (e.g. focusing on a rare comorbidity that isn’t relevant to the question). This could lead to answers that are too narrow or not generalizable. Mitigation: We will work with the OpenEvidence team during initial testing to make sure it uses patient context appropriately. If a pattern of over-narrow answers is seen, we can adjust the algorithm to find a more appropriate balance.
- Incorrect answers or reasoning errors: The LLM could get the answer wrong, or even if an answer is correct, it could be derived from a suboptimal citation. It’s possible that integrating complex patient data may lead to either inaccuracies or suboptimal citation retrieval compared to what OpenEvidence is currently trained to do. Mitigation: We plan a rigorous accuracy review process. In the pilot, every answer the system gives will be logged, and a sample will be reviewed by a team of UCSF hospitalists for clinical correctness. We will track the percentage of answers with significant errors. If above an acceptable threshold, we will iterate on the model (for instance, by providing more training examples or adding rule-based checks for certain high-risk questions). Users will also have an easy way to report a “bad answer” from within the UI, which will alert our team to review that case. Furthermore, the tool will carry a disclaimer reinforcing that it is an assistant – final decisions rest on the clinician. Encouraging users to verify critical suggestions via the citations is another safety check (and one of the reasons we insist on transparent sources).
6. How will we measure success?
We will define success using both quantitative metrics from system logs and qualitative/clinical outcomes. Our evaluation will include:
- Metrics from existing APeX data: Because the SMART app is launched within Epic (APeX), we can leverage backend analytics to capture usage patterns. Key metrics will include: the number of times the OpenEvidence app is opened (overall and per user per shift), the timing and duration of use, and the number of questions posed. We will also track how often users click on citation links to view more details – a proxy for how much they trust but verify the content. If possible, we will also examine workflow integration metrics such as: do clinicians tend to open the app on certain patients more (perhaps sicker patients or those on teaching teams) and at what points in the day (e.g. spikes during morning rounds)? A successful integration would show consistent usage (e.g. most hospitalists using it daily) and repeat usage by the same clinicians, indicating they found it valuable enough to come back.
B. Additional ideal measurements: We will complement the usage data with direct user feedback and clinical outcome assessments. This will involve:
- User surveys and interviews: We will administer brief surveys to the hospitalists and residents after they’ve used the tool for a few weeks. These surveys will gauge perceived impact on decision-making confidence, time saved, and trust in the AI’s recommendations.
- Comparative analysis (control groups): Ideally, we will design the pilot to include a comparison between different modes of information access:
- OpenEvidence with EHR context – the full integrated tool as described.
- OpenEvidence without EHR access – e.g. using the OpenEvidence app or web without patient context (so the clinician can ask questions but must manually input any patient details).
- UpToDate (or usual care) – clinicians relying on standard resources like UpToDate, guidelines, or consults, but not using OpenEvidence at all.
We can assign different ward teams or time blocks to different strategies and examine differences. Success would be reflected if the teams with EHR-integrated OpenEvidence report better qualitative outcomes than either control group.
7. Describe your qualifications and commitment
This project will be led by a UCSF faculty hospitalist with significant clinical and operational experience. Dr. Peter Barish is an Associate Clinical Professor of Medicine and is the Medicine Clerkship and Medicine Acting Internship director at UCSF St Mary’s Hospital. Dr. Barish has a long-standing interest in the field of clinical excellence and co-leads a biweekly DHM conference “Cases and Conundrums” as well as publishes a monthly newsletter (The CKC Dispatch) on current Hospital Medicine literature. He is also the UCSF co-site-lead of the national research study Achieving Diagnostic Excellence Through Prevention and Teamwork (ADEPT) where he and colleagues in DHM are currently investigating the use of LLMs to better understand and prevent diagnostic error.
He will be supported by Dr. Travis Zack, who is an assistant professor in the Division of Hematology/Oncology, an affiliate in the Department of Clinical Informatics and Technology (DoC-IT), the Computational Precision Health Program (CPH) and the Senior Medical Advisor for OpenEvidence. Additionally we have had discussions with OpenEvidence cofounder Zack Ziegler, who has enthusiastically expressed support for this project and will provide the engineers and technical expertise required to build the SMART on FHIR application here at UCSF (this would be the first integration of OpenEvidence within an EHR).
{kind=link}
Comments
This is an incredible idea.
This is an incredible idea. Open Evidence is a wonderful, easy to use application. With integration, it could sift through mounds of data without the need for my prompt. Once out of pilot model, we'd love to test in Primary Care!
Thanks Tyler for your support
Thanks Tyler for your support and your thoughts! We're very excited to collaborate with the Apex team to allow for that, and I agree, I think having to put a lot of info into an LLM prompt is incredibly time consuming and a big barrier to use.
Hi Peter, wonderful proposal
Hi Peter, wonderful proposal and idea - what are the licensing requirements to get Open Evidence and its API incorporated into EPIC? I'd imagine that might be a barrier?
Actually, we are working
Actually, we are working directly with the OpenEvidence team. They have never done this before but are interested in exploring the possibility of a direct in EHR build and are willing to have UCSF be the pilot.
Clinically meaninful
Clinically meaninful employment of AI that has the potential to increase evidence based decision making as a clinical decision support tool, potentially improving patient outcomes and improving clinical practice variability toward the evidence. Encouraged ongoing self directed learning by providing references and keeps the decision making in the clinican who has access to all of the data that is not available to the AI.
This sounds feasible. Has
This sounds feasible. Has the OpenEvidence team tried passing FHIR JSON data to their LLM to see if it can parse and interpret it appropriately? Can you get a letter of support for this project from the OpenEvidence team? Would the OpenEvidence platform save the question prompts and the specific patient information passed to it from the FHIR API? Would that constitute a privacy risk or other problem?
To a limited degree, but part
To a limited degree, but part of the value proposition for them is the ability to create, learn, and build such a system with a friendly institution. They are willing to commit and engineer and ML specialist to help build
Thanks much, Mark, for your
Thanks much, Mark, for your feedback. As Travis said, we're working directly with their team, but will see about uploading a short letter of support detailing this. And agree that the data sharing specifics are very important to ensure that no privacy issues are raised.
Great idea! Lots of potential
Great idea! Lots of potential use to improve efficiency and more pt-centered application of existing data/guidelines. Suggest highlighting "this would be the first integration of OpenEvidence within an EHR" much earlier in the proposal, as this is such a neat endeavor - ie, don't bury the lede! =)
Perhaps if the "ability to mark accuracy of both answer and provided citations" was made into a hard stop (pros/cons of this approach), this could be another trackable metric - and/or something like a thumbs up/down icon to indicate if user found it helpful or not.
Would be curious of: (1) any potential balancing measures (ie: to track any unintended consequences, if any meaningful), (2) if students would be included or not (mentions that hospitalists and residents would be surveyed), (3) specificity on what being surveyed "after a weeks" means (ex: for attendings, two consecutive clinical stints?)
Future state/wish list ideas:
* incorporating Micro, EKG, Radiology, Code Status
* Open Evidence highlighting strength/generalizabilty of each citation's evidence, risk-stratifying and/or prioritizing dx/mgmt options
* some type of equity measurement (both on user end and pt end of when this AI is utilized for)
Just noticing this is a
Just noticing this is a similar concept to Dr. Ben Rosner's separate proposal ("RAPIDDx: A Tale of 2 LLMs. Real time, AI-enabled, Point-of-care Intelligence for Differential Diagnosis"), so seems like a great opportunity for synergy/collaboration!
Agreed similarities. I
Agreed similarities. I believe this is a easier and more direct adaptation of OE, as DDx is not necessarily something OE is designed to do (vs evidence based answer support, and just expanding to include more patient information)
Thanks very much Andy for
Thanks very much Andy for your incredibly thoughtful feedback! Will definitely edit to not bury the lede so much. To respond to some individual points:
1. Good question re: whether to hard stop users to assess the accuracy. My sense is that would be a real barrier to daily use but we do want to ensure as much as possible that users are assessing for accuracy.
2. Would be very interested to discuss more about what balancing measures might be appropriate. Potential for something like measuring change in the use of diagnostic tests after LLM use, though I see a ton of confounders for any true outcome measures we'd be looking at.
3. Planning for attendings only at first, given the deisre to ensure as much oversight as possible, but could expand to other groups quickly depending on how the pilot progresses.
Really like your future state / wish-list ideas!