Section 1. The UCSF Health Problem
Problem Statement: Across UCSF Health, nearly 59,000 hospital discharge summary (DCS) narratives are manually written each year. As one of the longest, yet most important forms of clinical documentation, the DCS places substantial documentation burden on inpatient providers. Unfortunately, as both the literature and inpatient provider experience have shown,1 producing a high quality DCS in a timely manner is challenging. Whether providers are pressed for time, or are simply not aware of all of the details of a patient’s hospital encounter (the discharging physician at UCSF, is on average the last of 3 sequential physicians having cared for a patient, and therefore may not be aware of all events throughout the encounter), physician-written discharge summaries are not error free, as we recently demonstrated in a UCSF study accepted in JAMA Internal Medicine and is in pre-print.2 (Figure 1) Poor quality discharge summaries may then have multiple downstream ripple effects impacting subsequent quality of care and patient safety. 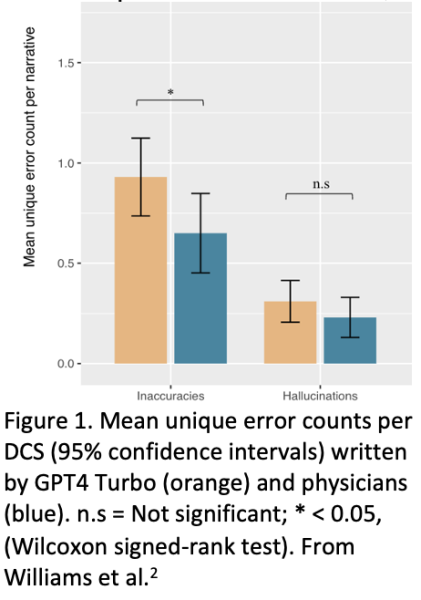
Background: The hospital DCS is an accounting of important hospital events and treatments that must be identified, synthesized, and composed by the discharging provider. A substantial contributor to documentation burden (often described as an epidemic3) is the DCS, a uniquely time intensive source of burden affecting not only all inpatient providers directly, but - depending on the quality of the summary – downstream providers too (e.g. primary care physicians, Skilled Nursing Facility physicians, and subsequent inpatient providers who commonly rely on reviewing the prior DCS when readmitting a patient).
The sequelae of this documentation burden include reduced face-to-face time on inpatient care, increased medical error rates, reduced document quality, physician burnout, and attrition. In one study, over 44% of hospital physicians reported not having sufficient time to compose high quality discharge summaries.1 Burden that is unique to the DCS derives from the need to review notes, procedures, and events throughout the hospital encounter (the longer the encounter, the more difficult the task); synthesize; reconstruct; and manually compose a problem-by-problem narrative of important hospital events and treatments. The discharging physician is often in the position of trying to reconstruct events that occurred before his or her care for the patient. Furthermore, because the hospital environment is a busy setting, with the physician taking care of multiple patients and being paged on average every 15 minutes (internal study), composing a summary is done either while the physician is on service in a highly interruptive environment - or done after hours in “pajama time.” Ultimately, not only is documentation burden recognized by leading healthcare organizations as a critical systemic problem, but it has also been designated by UCSF Health as a high priority IT Portfolio Initiative for FY2025 here. Additionally, by increasing the efficiency of DCS narrative production, an important secondary benefit of this proposal is helping facilitate discharge readiness earlier in the day, thereby opening inpatient beds earlier and decompressing the number of patients boarding in the emergency department (also a UCSF priority). Therefore, this proposal aligns with several existing UCSF priorities.
Section 2. How might AI help?
AI assistants are already being piloted in many health systems to reduce documentation burden through ambient scribing (USCF is currently piloting this technology), and AI-generated draft responses to inbox messages, noting statistically significant reductions in burden and burnout.4 Although AI’s potential for higher-stakes use cases such as medical decision making is still being explored, LLMs are well-known to excel in lower-stakes use cases such as medical summarization.5 We have already demonstrated safety and feasibility of using Versa for generating the DCS narrative by reading through all hospital encounter notes and comparing GPT-4 Turbo’s output to physician-generated summary narratives in a retrospective study that has been accepted for publication by JAMA Internal Medicine. According to processes outlined by the UCSF AI Governance Committee here, the next step following the retrospective analysis we did for the JAMA IM paper, would be a prospective pilot, which we are hereby proposing.
While the proposed pilot targets DCS for the Hospital Medicine service (as in our JAMA IM paper), the value of an LLM-drafted discharge summary has tremendous potential to scale across all inpatient specialty services at UCSF.
Section 3. How would an end-user find and use it?
An end-user would invoke the LLM-generated DCS narrative directly in the existing discharge summary workflow in APeX. (Figure 2A) As discussed with the APEx Enabled Research (AER) team on March 10, 2025, any inpatient provider writing a hospital DCS could optionally launch the LLM simply by following the usual workflow and clicking on “Discharge Summary” that would then be followed by the option to choose an LLM generated draft for provider review. Because Versa is HIPAA-compliant, UCSF is uniquely positioned to do this work and become a national leader in LLMs for the DCS.
Section 4. Embed a picture of what the AI tool might look like (Figure 2)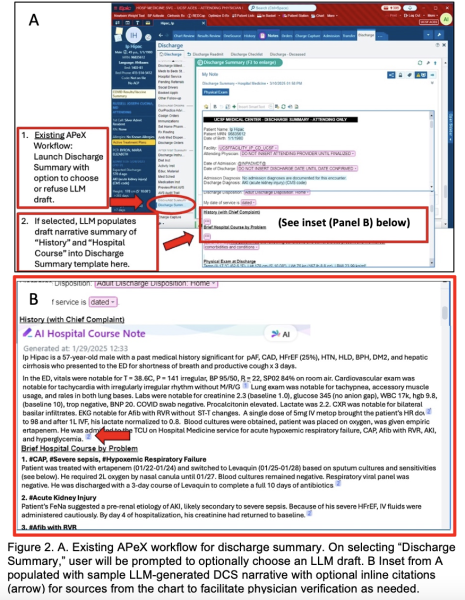
Figure 2A shows the existing APeX workflow for generating a discharge summary. The inpatient provider selects “Discharge Summary” from within the Discharge Navigator tab, opening a Discharge Summary template. Many of the items in the template (e.g. medication list, referrals, etc.) will auto-populate from APeX. However, the summary narrative (“History (with Chief Complaint)” and “Brief Hospital Course by Problem”) must currently be manually composed by the inpatient provider. This is the section that involves the most documentation burden. Figure 2B shows sample LLM output where the drafted discharge summary narrative would be placed and available for provider review. Furthermore, Epic has the ability to optionally include citations /links associated with LLM-generated statements to information sources from the hospital encounter, thereby facilitating review and verification by the provider.
Section 5. What are the risks of AI errors?
The proposed use of AI for the DCS involves human-in-the-loop. Namely, inpatient providers must review LLM-drafted DCS much in the same manner as they must review drafted inbox replies to patients. It remains the inpatient provider’s responsibility to ensure the accuracy of the DCS. Nevertheless, in our retrospective study, not only did we find that providers reviewing the summaries (blinded as to whether the summary was LLM- or physician-generated) had equal preference for both (χ2 = 5.2, p=0.27), and that they had similar overall quality ratings (3.67 [SD 0.49] vs 3.77 [SD 0.57]; p=0.674), but that there was no difference in the harmfulness scores associated with each LLM vs. physician error. While accurate medical summarization is important, (we found that physicians also made errors of omission, inaccuracy, and even hallucinations), the stakes of AI use for medical summarization with human-in-the-loop are lower than for AI used in medical decision making. Finally, identifying errors in the LLM-generated content could optionally be accomplished by enabling a reporting button within APeX with which inpatient providers could report potential errors for further investigation and mitigation. We also hope to be one of the first use cases for UCSF’s Impact Monitoring Platform for AI in Clinical Care (IMPACC), which is being built for continuous, automated, longitudinal AI monitoring.
Section 6. How will we measure success?
There are many potential approaches to deploying the intervention and metrics to measure success. In this high level overview, it is critical that the deployment approach minimizes the friction to existing clinical workflows that could limit adoption and user satisfaction. We therefore propose an observation cohort approach allowing each inpatient provider to have the option to choose an LLM-drafted summary for each patient. Although a randomized controlled trial (RCT) – either randomized at the provider level (certain providers opted in for all of their patients) or at the patient level (same provider could use the LLM drafts for some patients but not others) – would offer the most rigorous evidence, an RCT could cause substantial workflow friction.
Therefore, we will measure success in an observational cohort study on two main domains:
- Measurements using data already being collected in APeX: Leveraging the APeX audit logs, an area of deep expertise in our research group, we will assess the burden on inpatient providers using the LLM-drafted content by: 1. Measuring the amount of manual editing of the LLM-drafted narrative the provider makes (character count and % of narrative text edited as proxies for burden), and 2. Time savings as measured by the amount of time spent either editing LLM-drafted narratives or composing provider-generated narratives.
- Measurements not necessarily available in APeX, but ideal to have: In any new technology deployment, user satisfaction is important to capture. If possible, we will attempt to capture user satisfaction with the LLM-generated narrative process by collecting Net Promoter Scores from inpatient providers using the LLM-drafted narratives, as well as those who are downstream recipients (e.g. PCPs, SNF physicians). Also ideal, if possible, would be to capture in APeX, inpatient provider flags of potential errors (inaccuracies, omissions, hallucinations), not only as a measure of quality and safety, but for investigators to identify concerns, and develop mitigation strategies. Optionally, the investigator team can quantify these error types, or (in a more scalable approach) we could potentially embed a multi-agentic platform such as CrewAI (crewai.com) to allow multiple LLMs to check one another for errors.
Section 7. Describe your qualifications and commitment:
This project is led by Dr. Benjamin Rosner, MD, PhD, FAMIA. Dr. Rosner is a hospitalist, a clinical informaticist, an AI researcher within DoC-IT, and the Faculty Lead for AI in Medical Education at the School of Medicine. He has years of experience developing, testing, and deploying digital technologies into healthcare, and he was the lead author of the retrospective study that underpinned the evidence for this solution. Dr. Rosner has worked directly with AER through the Digital Diagnostics and Therapeutics Committee (DD&T) for 6 years.
Charu Raghu Subramanian, MD is a Clinical Informatics Fellow, a hospitalist, and a co-lead author on the retrospective research study that underpinned the evidence for this pilot. She holds certifications in Epic Clarity and as an Epic Builder.
Citations
2. Williams CYK, Subramanian CR, Ali SS, et al. Physician- and Large Language Model-Generated Hospital Discharge Summaries: A Blinded, Comparative Quality and Safety Study. medRxiv. September 30, 2024. doi:10.1101/2024.09.29.24314562 https://www.medrxiv.org/content/10.1101/2024.09.29.24314562v1 (also accepted for publication in JAMA-IM, with anticipated publication in May, 2025)
Summary of Open Improvement Edits
- Added suggested measurement concepts to allow inpatient providers to flag potential errors (inaccuracies, omissions, hallucinations)
- Added option for investigator team to quantify errors
- Added option for multi-agentic platform to identify and quantify errors
- Added Medrxiv link to manuscript in citation #2 (to be published in JAMA-IM in May, 2025)
Comments
Thoughtful approach for AI to
Thoughtful approach for AI to address important, high-yield, and time-consuming "low hanging fruit" for busy clinicians who are increasingly being pulled in numerous directiorns, esp as it builds upon an existing proof-of-concept study led by Dr. Rosner, Dr. Subramanian, and colleagues. Much of the current APEX DC Summary process is significantly and negatively affected by copy/paste, suboptimal content synthesis (and generation), and poor formatting leading to "note bloat", complicating the role of the final physician creating the DC Summary. As a primarily clincian-educator, I can very much see this improving my workflow and efficiency. Certainily will need to be balanced by what is described above as "human in the loop" to ensure accuracy, as well as longitudinal monitoring to avoid any inadvertent and unintended consequences, but I'm very optimistic about the potential of this approach.
As a participant in this
As a participant in this proof of concept I was encouraged by the ability of LLM to augment our clinical documentation aprticularly around improving discharge instructions and discharge summaries. Endorse this proposal for leveraging AI to improve clinical workflows.
This is an important project
This is an important project to continue to improve the AI ability to construct discharge summaries. As a participant of their previous project, I was impressed with how AI can create discharge summaries. However, further refinement and continued study is needed before we can entirely rely on AI generated discharge summaries. Dr. Rosner, Dr. Subramanian, and colleagues have the knowledge and expertise to continue this project.
AI-assisted discharge
AI-assisted discharge summaries have the potential to improve clinical documentation efficiency, particularly by addressing issues like note bloat, poor formatting, and suboptimal content synthesis. Previous proof-of-concept work led by Dr. Rosner, Dr. Subramanian, and colleagues has demonstrated promising results, especially in enhancing discharge instructions and summaries. While AI can significantly augment workflow for busy clinicians, maintaining a "human in the loop" approach is essential to ensure accuracy and mitigate unintended consequences. Continued refinement and study will be necessary before fully relying on AI-generated summaries, but this project has strong potential to enhance clinical workflows.
This will be hugely
This will be hugely beneficial in helping physicians document discharge summaries in a more complete way allowing for increased billing from these notes. Additionally this would allow physicians to save time in documentation allowing for more time spent conducting patient care. Dr. Rosner, Dr. Subramanian, and colleagues have significant knowledge and expertise in this work. I believe this will be practice-changing and very impactful.
This seems like a good idea.
This seems like a good idea. In your measures of success, do you want to have any additional measures of accuracy/errors/hallucination? Also, can you attach reference 2?
Thank you for the thoughtful
Thank you for the thoughtful feedback Mark.
With respect to inaccuracies, omissions, and hallucinations, measuring these remains a manual process. However, I see 3 potential avenues to accomplish this, 2 of which are manual, and 1 of which would be brand new and use a multi-agentic platform such as CrewAI to have LLMs check one another for errors. The 2 manual approaches could be: A. Incorporating physician self-reporting buttons for each error type (is this done for inbox messages drafted by Verda? If so, we could re-use that infrastructure), or B. The investigator team assessing for errors. I have added these concepts to the proposal.
With respect to reference 2, I hav added the URL. The manuscript has also been accepted in JAMA -IM and is slated for publication within a few weeks. https://www.medrxiv.org/content/10.1101/2024.09.29.24314562v1
There is a lot of demand for
There is a lot of demand for this feature. We definitely want to have a comprehensive review process for errors of omission and other inaccuracies as I think we share the concern that providers will become increasingly reliant on this tool likely leading to less individual chart review.
Good point, and we can
Good point, and we can definitely do that. It's noteworthy that physicians themselves have a considerable number of omissions - as seen in our study. So, a benchmark for the LLM need not be "perfectionion" but whether the LLM can improve current practice not only in terms of omissions, but in terms of reducing clinician burden, and increasing several measures of quality, not unlike the way that LLMs are being used and evaluated for drafting inbox responses.
This is the 'holy grail' of
This is the 'holy grail' of using AI tools to make physicians' tasks easier to prioritize the higher-value tasks - with AI-generated D/C/Summs, physicians can focus on expressing decision-making rather than regurgitating and summarizing information. It was fascinating to review this pilot work which clearly showed that the LLM can serve as a useful tool to document concisely, clearly, and efficiently.
This work is so important and
This work is so important and this is a great use of how AI can be used thoughtfully by clinicians to reduce documentation burden and give clinicians more time with patients and less time with computers. I was part of the initial work here and think this is a very promising start that is ready to move into the next phase to be implemented correctly and also continue to expand/test for our increasingly complicated patient population.
Very innovative and
Very innovative and clinically meaningful work that has the potential to improve physician experience and have meaning throughput improvements.
Given that medical
Given that medical documentation prioritizes information synthesis over creativity, AI's integration into this domain can substantially enhance healthcare quality. As many suggested here, employing AI in the preparation of discharge summaries may allow physicians to allocate more time to direct patient care while simultaneously mitigating physician burnout. This study is poised to serve as a landmark contribution to future research on AI's role in medical documentation.
Great project! Very well
Great project! Very well thought out. I like the evidence-based assessment of accuracy and feasability. I'm curious if you have any guess as to the amount of time this tool would save per encounter? Also, do you think it would change the tendancy of providers to copy-forward information in progress notes that are less about daily progress and more about keeping track of hospital events so that it's easier to write a discharge summary at the end?
Thanks, Seth. I think there
Thanks, Seth. I think there are at least two types of users who may experience different time savings or benefits from this. There are those who tend to copy/forward the most recent progress note and repurpose it for a discharge summary. For them, there may not be a lot of time savings, but I suspect that the quality of the note, and the note truly reflecting the full course of the hospitalization may substantially improve. For others, those who spend time looking back through progress notes, consult notes, etc., in the process of composing a discharge summary narrative, this may save considerable time, and still also improve quality (since there's no practical way for a human to examine all notes, but the LLM can). As part of this proposal, we plan to measure the time it takes to receive and then edit an LLM-drafted summary, compared to those who do not use the LLM to draft the discharge summary at all.
As prior commentors have
As prior commentors have mentioned, this is a very high-impact project for the "everyday" hospitalist. Beyond the proposed benefit of reducing cognitive burden and saving time so the clinician can divert time to where it matters (at the bedside, with the patient), this project positions UCSF to be a leader in developing high-quality HIPAA-compliant AI-generated narratives for the complex patients seen in our health system, who are more prone to errors. Though not an explicit primary benefit, if following the pilot period this tool is sharpened and is available to trainees (students, residents, fellows) and APPs on other service lines, it would potentially improve the quality of narrative writing beyond DCS to interservice or interhospital transfer summaries (further reducing note bloat, documentation errors perpetuated by copy-forward notes). Outstanding proposal, I'm excited to see this project's leads' next steps!