1. The UCSF Health Problem
Patients at UCSF Health who receive immunosuppressive medications (e.g., disease modifying drugs (DMARDs) like methotrexate or biologics) require frequent laboratory monitoring to detect potential toxicities such as liver enzyme elevation, cytopenias, elevated blood pressure, organ dysfunction, or opportunistic infections. Although guidelines recommend regular laboratory monitoring, these processes rely on manual workflows during clinic visits and are unfortunately ad hoc in nature, leading to significant patient safety risks. Further complicating monitoring, tests may be performed in outside laboratories and therefore only captured in clinical media in pdf form (or discussed during the visit) within the EHR. National studies done by our team also demonstrate that critical safety monitoring for immunosuppressive medications frequently is not done or delayed.12 As a result, patients may face delayed therapy adjustments and unnecessary risk of medication-induced harm, with crucial lab values or infection screenings failing to surface in real time. Existing methods—such as manual spreadsheets or nurse phone reminders, are labor-intensive and difficult to scale. Operational leadership in rheumatology at UCSF has identified development of improved lab monitoring systems as a high-priority target for improvement, noting that automated, comprehensive approaches could significantly increase efficiency, reduce legal risks to the institution, and most importantly, enhance patient safety.
2. How Might AI Help?
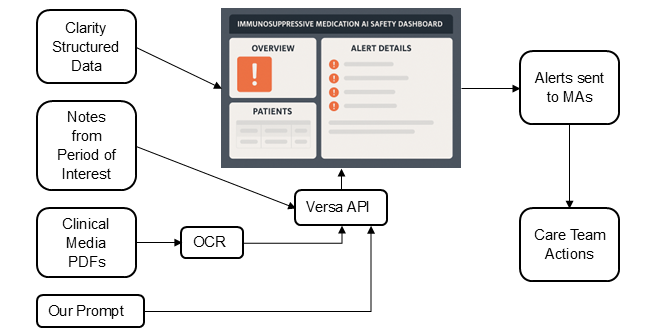
We propose an AI tool to automatically monitor drug safety gaps. The tool would identify patients overdue for recommended labs based on medications, laboratory data, outside lab tests contained in PDF documents, and labs that were entered by clinicians in notes. We envision this tool as a system with a dashboard as the frontend; the dashboard would streamline tracking of required safety tests, while minimizing false alarms regarding missed screenings, and reducing the need for manual chart review, both increasing safety and decreasing administrative burdens. Specifically:
- The tool will select patients who are currently receiving a medication of interest that requires periodic testing, including oral DMARDs and biologic drugs. Required tests and their limit dates will be kept in a table the tool has access to, such as a csv file, which is updated daily.
- The tool will then retrieve all relevant structured EHR data (laboratory results and other relevant screenings) for patients and flag those with significant delays in monitoring. By using existing branching algorithms and prior experience with Clarity pulls, we could quickly implement this real-time data pull using LOINC codes. For example, methotrexate requires laboratory monitoring every 3 months; the tool will flag all patients who do not have evidence of monitoring in the last 5 months. This grace period will identify patients who are clearly outside guideline recommended screening windows.
- For flagged patients, the tool will then leverage Versa through the API, screening notes and patient portal messages from recent visits for mention of labs and tests of interest that may have been performed externally. For PDF documents in clinical media, the tool will use an OCR algorithm (or Python extraction if digital) followed by Versa. If information is found, the tool will update its data, removing the flag, indicating that the patient did receive their periodic testing in time, and presenting lab results in the dashboard. This will allow us to avoid Versa running unnecessarily. We have prior experience in prompt design and in-context learning methods using Versa for information extraction, even when the information is not explicitly available but requires model reasoning, and will use this expertise here.3
- The AI tool will raise a warning for all patients that remain flagged (i.e. no testing data found in either structured data, notes, or clinical media PDF files).
- The loop will be repeated as needed to ensure patients continue to receive their safety testing. The loop will also include criteria for exclusion (for example, the medication is no longer prescribed, or the patient is no longer seen at the clinic, with functionality for staff to update this latter component in the platform). We will explore how often to re-send alerts that are not acted upon, and re-run the loops, through qualitative interviews with the care team.
3. How Would an End-User Find and Use It?
The AI tool would run in the background and require no UI. Interaction is limited to: (1) MAs receiving alerts, who will then communicate with other members of the care team and patients as needed, and (2) loop results saved in a dashboard the care team can consult. The dashboard, which will be iteratively designed with clinical staff, may also include search functionality to customize checks for individual patients (e.g., a patient that has a comorbidity that requires more frequent monitoring) as well as have a feedback option, so that the study team can monitor problems as they come up. The figure below presents a diagram of our proposed model.
4. What Are the Risks of AI Errors?
- False Positives: The system might raise a false alarm by missing documentation of a lab that has already been completed and documented in the EHR. To mitigate this risk, we will do extensive testing with human annotators and staff during pilot testing specifically asking if they have observed any false positives, and if so, we will retrain/adjust the model. We will ensure this risk is minimal by conducting chart review and model evaluation during an initial proof of concept phase. Once fully implemented, model maintenance will include regularly scheduled validation to ensure the model continues to function properly, preventing model drift. Feedback collection will be integrated in the dashboard.
- False Negatives: The system fails to detect a truly missed test. The feedback system designed above will also detect and mitigate this risk if present. We will also assess the prevalence of false negatives during the proof-of-concept phase and regularly though implementation.
- Hallucinations/Omissions: Versa incorrectly extracts lab data from notes (leading to either a false negative or a false positive). We consider this risk as a special case of both risks defined above as retraining Versa if this occurs would not be possible. While the risk of misreading old results as current is low since we will only add notes from the relevant time period, past labs may still be discussed in those notes. If this risk is observed, we will try to mitigate it through prompting techniques such as metaprompting and chain of thought, or by using a smaller, local model we are capable of fine-tuning, such as ClinicalBERT.
We will further mitigate these risks by tracking real-time use and outcomes; for example, how many flagged alerts led to ordered labs, indicating a lab was indeed past due. We also place a human in the loop, as MAs will interact with the dashboard and report to clinicians and nurses.
5. How Will We Measure Success?
Our plan is to pilot the AI tool in the UCSF Rheumatology clinic during the first year. We aim for a model that is fully implemented and collecting use data by the end of the first year. If effective, we will seek to extend to other UCSF clinics using medications that require toxicity monitoring, such as gastroenterology, dermatology and nephrology. We propose:
During model design and proof of concept (Months 1-3): We will manually chart review a statistically representative sample of our dataset of potential gaps identified by the AI tool with 2-3 UCSF rheumatologists, indicating how many identified gaps were true positives, using classic machine learning metrics (F1, precision, recall, AUROC), as well as correctness of retrieved data. This will also serve as an evaluation set for any future changes to the model. We will continuously add data to this evaluation set throughout pilot testing.
During implementation and pilot testing (Months 4-12):
- Changes in lab completion rates: Proportion of patients on target medications who complete missed labs detected by the AI tool within guideline-specific intervals.
- Number of missed tests identified by Versa missing in structured data.
- Performance of different prompts and models, in clinical media and in notes, using classic ML metrics, including correctness of retrieved lab values from notes and PDFs.
- Time-to-order: Time, in days, from gap detection to lab order and to lab completion.
- Provider feedback: We will interview 2 clinical staff each week for the first week of implementation, followed by every other week until conclusion of the pilot or complete removal of false positives, false negatives, and hallucinations.
- Provider satisfaction: At the conclusion of the pilot test, we will interview 5-6 UCSF rheumatologists and nurses (or until thematic saturation) on their perspective of the AI tool using semi-structured interviews following the technology acceptance model.
If we achieve excellent accuracy (>97% correct assessments) we will explore the possibility of further automating the process by generating pended lab orders for clinicians to sign.
6. Qualifications and Commitment
Project co-leads: Augusto Garcia-Agundez, PhD. Postdoctoral researcher at the Division of Rheumatology. Expert in AI methods and NLP. Dr. Garcia-Agundez will commit 10% effort to implement and validate AI methods and conduct continuous evaluation. Jinoos Yazdany, MD MPH. Chief of the Division of Rheumatology at ZSFG and the Alice Betts Endowed Professor of Medicine at UCSF. Dr. Yazdany has ample experience in quality improvement projects and prior experience designing EHR add-on tools such as a dashboard for Rheumatoid Arthritis. Dr. Yazdany will commit in-kind effort for the year to collaborate with UCSF Health AI and APeX teams. Co-Is: Gabriela Schmajuk, MD, MSc. Chief of Rheumatology at SFVAHC and Professor of Medicine in the Division of Rheumatology at UCSF. Andrew Gross, MD. Dr. Gross is Medical Director of Rheumatology at UCSF. Diana Ung, PharmD, APh, CSP. Dr. Ung is the UCSF Specialty Pharmacist for Rheumatology. Nathan Karp, MD. Director of QI for Rheumatology at UCSF.
7. Summary of Open Improvement Edits
Added clarification about existing preliminary work including branching algorithms for required labs and timeframes, and knowledge of where to pull the required data from Clarity.
Comments
This is a really interesting
This is a really interesting project and I'm excited to see where this goes. I feel like the the need for frequent lab monitoring and the realistic relatively low adherence with monitoring guidelines has led to some people shying away from prescribing otherwise effective and appropriate therapy. This proposal could help bolster confidence in safety monitoring and really help us take great care of our patients.
The proposal here is feasible and high impact. I appreciate the thoughtful and thorough discussion of potential AI errors here, as well as the proactive steps taken to mitigate these risks. In addition, this proposal has natural extensions and applications in a variety of domains. For example, I think an OCR workflow that could review outside labs or documentation and integrate it in the EMR would be fantastic and greatly help with chart review burden and errors.
I believe this project may
I believe this project may require programming an APeX-integrated application with extensive built-in logic (e.g., for each patient/monitored drug, what is expected time to next labs, what lab ranges are normal, what is the schedule for first/second/third reminder, when to call Versa to interpret a clinical note, etc) that would take a fair bit of programming. Does that sound right? Do you have a plan or prototype for building this application?
Thank you for your comment,
Thank you for your comment, Dr. Pletcher. You are correct that this project will involve a fair amount of programming, but as a lab focused on quality measurement and data science, we have ample preliminary work to build on. We’ve already developed branching logic algorithms for immunosuppressive medications detailing the specific lab tests, recommended intervals, and grace periods, and we know where to pull this data from within Clarity, including the relevant tables and LOINC codes (and have the expertise to do so). Our team also has experience building data pipelines and dashboards, including an existing Salesforce-based application we developed in collaboration with SOMTech. The reason we are proposing this pilot is because these methods by themselves still miss patients who completed their labs externally, and as such the data would be missed unless we look at the notes and clinical media. This approach needs AI & NLP to create a system that increases safety without adding burden to clinicians caused by false alarms and manual chart review. We expect Versa's addition will help us put this system into practice within the one-year proposed timeframe.
This proposal is feasible and
This proposal is feasible and the intervention is potentially high-impact. The team conducting this work has the track record and expertise to execute this proposal. If we can safely implement this type of intervention, it will undoubtedly make it easier for clinicians to keep track of lab monitoring for their patients and as a result help them provide consistent high-quality care of patients with complex diseases. There is so much to do in a visit with a patient that has a complex, immune-mediated/autoimmune condition. One critical and time-consuming aspect is safety monitoring with the use of immunosuppressive treatments. Often there are multiple medications that require repeated lab monitoring, these medications are not all on the same monitoring schedules, and labs are not always done within the health system. It’s a lot for a clinician to keep track of and hunt down, and it is not a good use of a clinician’s time and skills. This task seems ripe for technology to help us do better.