Improving Surgical Site Infection Reporting using AI
The UCSF Health Problem
Surgical site infections (SSIs) remain the leading surgical complication, contributing to increased morbidity, mortality, extended hospital stays, and significant healthcare costs. Manual surveillance methods, while essential for accurate SSI identification, are resource-intensive and hinder infection preventionists from focusing on prevention efforts. Current semi-automated methods, relying on structured data triggers such as microbiology results or reoperations, have low positive predictive value, leading to extensive manual chart reviews. Given the national priority to improve healthcare-associated infection (HAI) surveillance, there is an urgent need for an automated, AI-driven approach to improve efficiency and accuracy. The primary end-users of the proposed AI solution are infection preventionists who conducted SSI surveillance at UCSF Health and other healthcare institutions.
How Might AI Help?
Artificial intelligence, particularly generative AI and large language models (LLMs), can transform SSI surveillance by synthesizing complex, unstructured clinical data into meaningful insights. Our AI solution will analyze electronic health record (EHR) data, including provider notes, microbiology results, and interventional radiology reports, to identify deep incisional and organ-space SSIs with high accuracy. The AI will reduce the number of surgical cases requiring any manual chart review and for patients identified as likely to meet the definition of a deep or organ space SSI, the amount of time required per chart to complete surveillance will be reduced through the creation of a concise clinical synopsis of key infection-related clinical events. Importantly, in the long term, automating this process has the potential to improve the timeliness of infection detection and reduce the number of infection preventionists required to conduct surveillance. The latter is both cost savings as well as potentially critical as we are facing a national shortage of infection preventionists. AI models will be trained using NHSN criteria and validated against historical UCSF SSI outcome data to ensure reliability and clinical utility, as well as tested prospectively side-by-side to the current EHR-embedded tool over a defined evaluation period.

How Would an End-User Find and Use It?
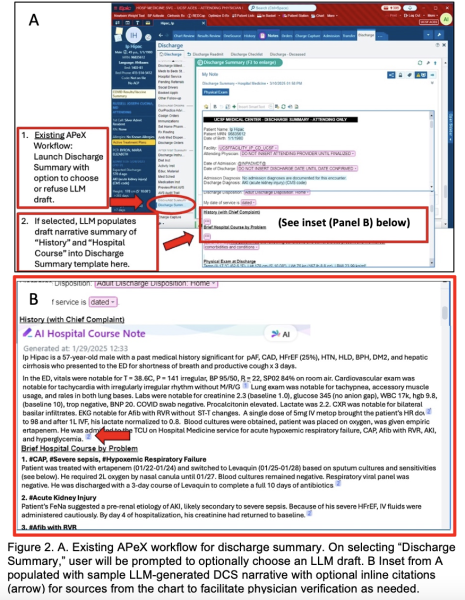
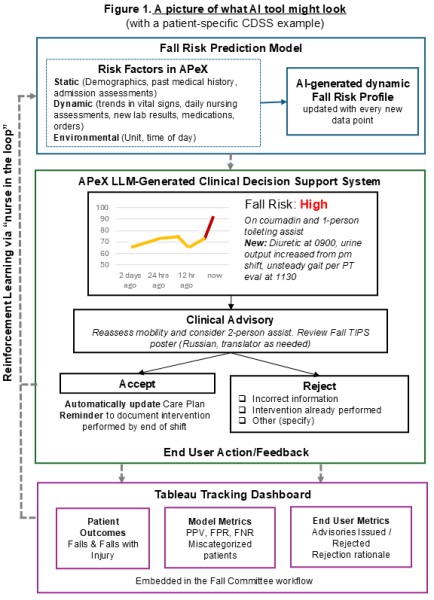
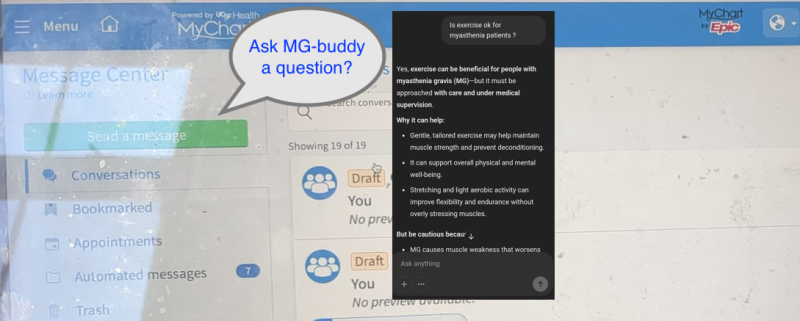
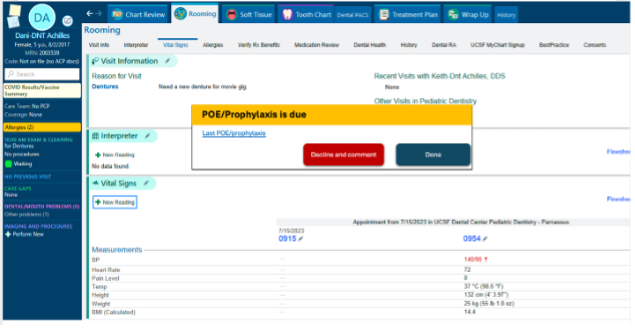
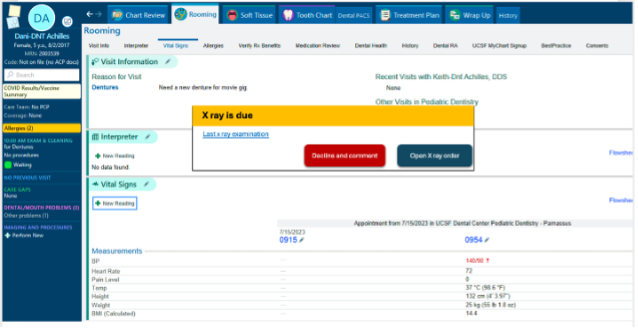
The AI tool will be integrated within UCSF’s APeX EHR system, presenting infection preventionists with a streamlined workflow. The tool could be automated to run in the background on a daily basis, and when a potential SSI is identified, a flag and short AI-generated infection summary would be added to the patient’s chart. These patients could then go into a workqueue for infection preventionists to review, and either confirm or override the AI’s determination. This reduces the time spent per patient while maintaining a human-in-the-loop approach for final decision-making. This will be particularly useful during routine surveillance activities, allowing infection preventionists to focus on true positive cases rather than spending time on false leads.This also does not significantly alter the current infection preventionist workflow, which depends on reviewing cases in a workqueue, so the training required to adopt this new proposed workflow should be minimal.
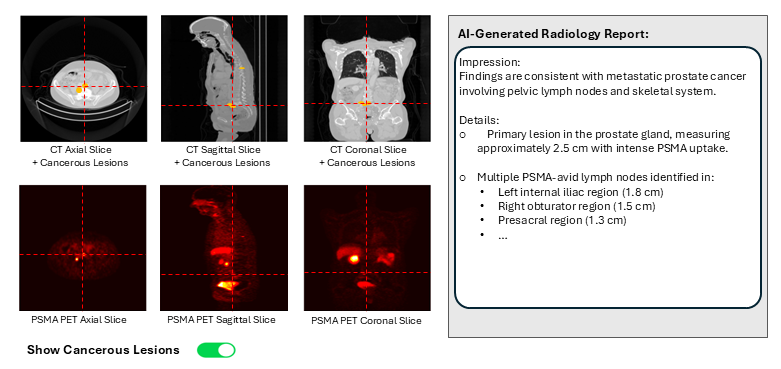
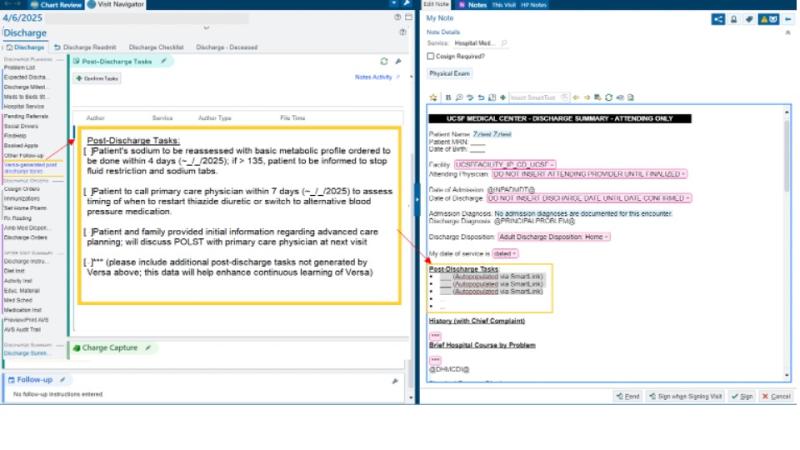
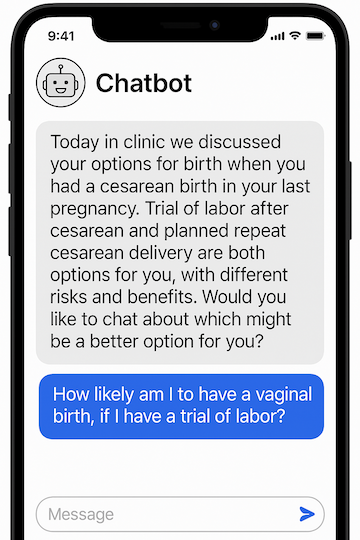
Example of AI output

What Are the Risks of AI Errors?
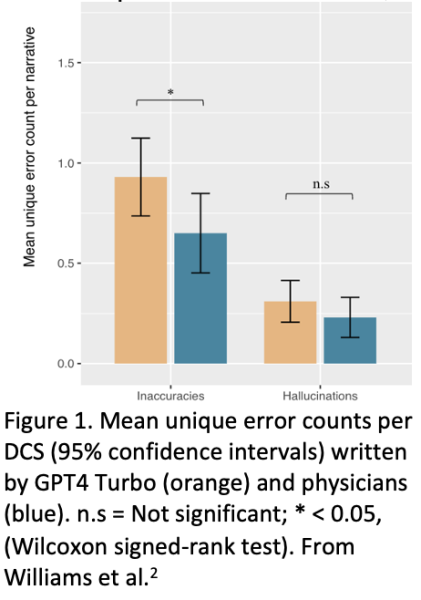
AI-based SSI detection introduces risks such as false positives, false negatives, and AI hallucinations (erroneous conclusions). False positives may result in unnecessary investigations, while false negatives could lead to missed SSIs, impacting patient safety and regulatory compliance. However, thus far, this tool has been tested on a subset of NHSN cases from 2024 and maintains a 100% negative predictive value when compared to current SSI reporting.
To mitigate these risks, our model will undergo rigorous validation with retrospective and prospective datasets. Continuous performance monitoring, bias assessment, and iterative refinements will ensure accuracy. The AI tool will always function as an assistive technology rather than an autonomous decision-maker, with infection preventionists retaining ultimate control over SSI determinations.
How Will We Measure Success?
We will assess success based on adoption, impact on infection preventionist workflow efficiency, and improvements in SSI detection rates. Metrics include:
a. Measurements using existing APeX data:
- Number of SSIs detected pre- and post-AI implementation
- Time spent per chart review (EHR audit logs)
- Positive predictive value (PPV), negative predictive value (NPV), sensitivity and specificity of AI-generated determinations
- Given that this is intended to be a screening tool, we will prioritize maximizing sensitivity and negative predictive value to ensure that potential SSI cases are not missed. We will also work closely with the UCSF infection prevention group to ensure any potential tradeoffs are balanced and reasonable for their workload.
- Infection preventionist workload reduction (number of cases reviewed)
b. Additional measurements for evaluating success:
- Infection preventionist user satisfaction surveys
- Qualitative analysis of AI explanation trustworthiness
- Analysis of bias across demographic and clinical subgroups
- Impact of tool on SSI standardized infection ratios
Describe Your Qualifications and Commitment
This project is spearheaded by Elizabeth Wick, MD (Colorectal Surgery, UCSF Vice Chair of Quality and Safety), Deborah Yokoe, MD, MPH (Infectious Diseases, UCSF Medical Director for Hospital Epidemiology and Infection Prevention), and Logan Pierce, MD (Hospital Medicine/DoC-IT, Managing Director of Data Core). This interdisciplinary team, comprising infection prevention experts, surgeons, informaticists, and infection preventionists is committed to refining and deploying this AI-assisted surveillance tool.
Elizabeth Wick, MD, is a Professor of Surgery and Vice Chair for Quality and Safety in the Department of Surgery at UCSF. She is an expert in surgical quality improvement and SSI prevention and has led multiple national initiatives focused on improving surgical outcomes. Dr. Wick has extensive experience with NHSN surveillance methods and has been instrumental in developing strategies to reduce the burden of manual data collection. She will provide leadership in integrating AI solutions into infection prevention workflows and ensure that the project aligns with national quality improvement priorities.
Deborah Yokoe, MD, MPH, is an international leader in healthcare epidemiology and infection prevention. As the Medical Director of Infection Prevention and Control at UCSF Health, she has a deep understanding of NHSN surveillance definitions and infection preventionist workflows. Dr. Yokoe has played a key role in shaping national infection prevention strategies and brings critical expertise in evaluating AI-generated SSI determinations. She will ensure that AI implementation is clinically sound and supports infection preventionists in making accurate and timely SSI identifications.
Logan Pierce, MD, is board-certified in both clinical informatics and internal medicine. He is the Managing Director of UCSF Data Core, a team of physician data scientists dedicated to utilizing EHR data to improve healthcare outcomes. He has experience using large language models to extract data from clinical text. Dr. Pierce will actively contribute throughout the development lifecycle, ensuring alignment with UCSF Health priorities and participating in regular progress reviews with Health AI and AER teams.


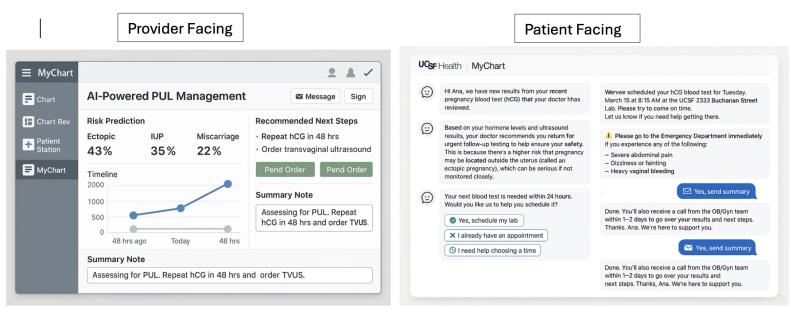
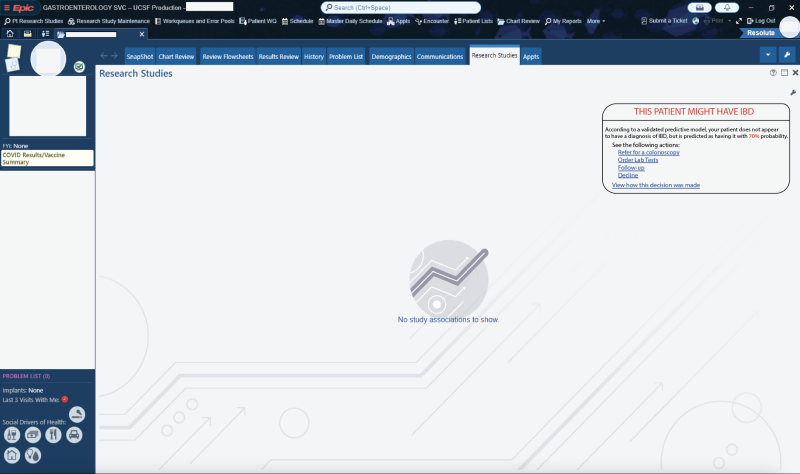


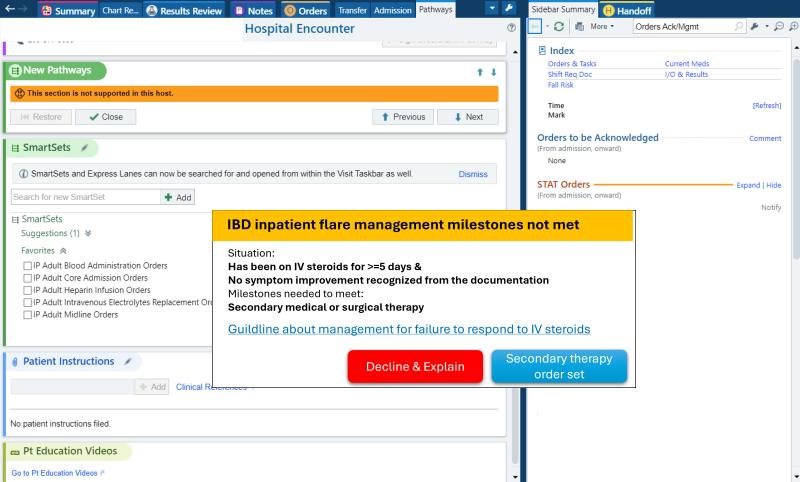
 potential opportunities for differential diagnosis (as well as a vast array of other use cases that could be governed with “prompt order sets”) if these LLMs were integrated into APeX and could examine the
potential opportunities for differential diagnosis (as well as a vast array of other use cases that could be governed with “prompt order sets”) if these LLMs were integrated into APeX and could examine the 

















 Project plan:
Project plan:

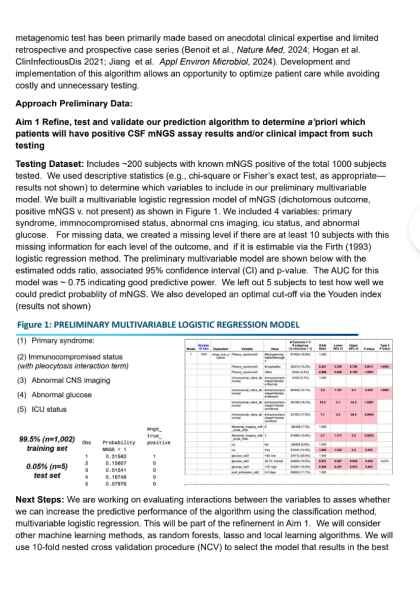






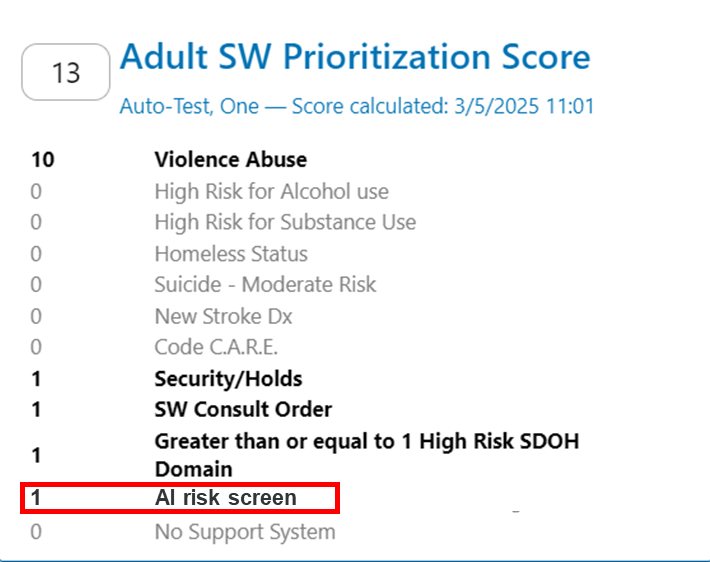
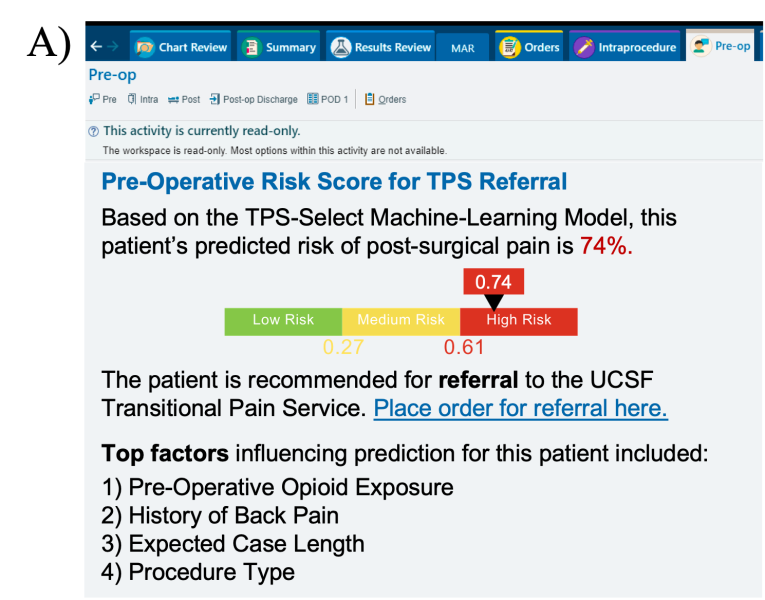
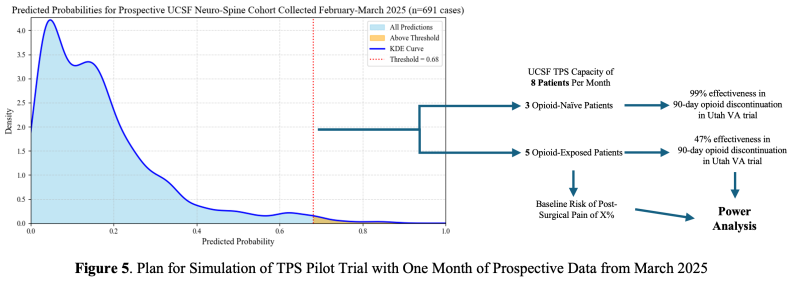
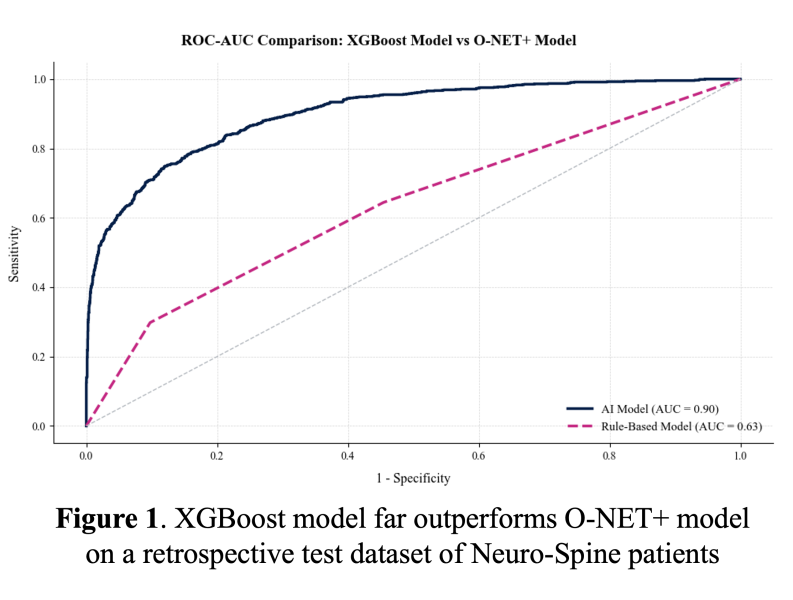 For comparison, the positive predictive value was 0.97 with our XGBoost model and 0.43 with the O-NET+ tool at the 0.68 threshold selected based on prospective validation results (Figure 5), highlighting our model’s superior specificity in identifying true high-risk patients compared to broader, less discriminating traditional criteria. Using the AI Pilot Award, we aim to silently prospectively validate this model to demonstrate that our model better identifies high-risk Neuro-Spine patients for TPS referral in the clinical setting compared to traditional methods.
For comparison, the positive predictive value was 0.97 with our XGBoost model and 0.43 with the O-NET+ tool at the 0.68 threshold selected based on prospective validation results (Figure 5), highlighting our model’s superior specificity in identifying true high-risk patients compared to broader, less discriminating traditional criteria. Using the AI Pilot Award, we aim to silently prospectively validate this model to demonstrate that our model better identifies high-risk Neuro-Spine patients for TPS referral in the clinical setting compared to traditional methods.
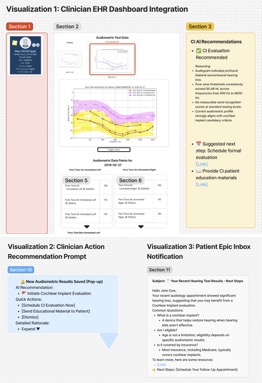
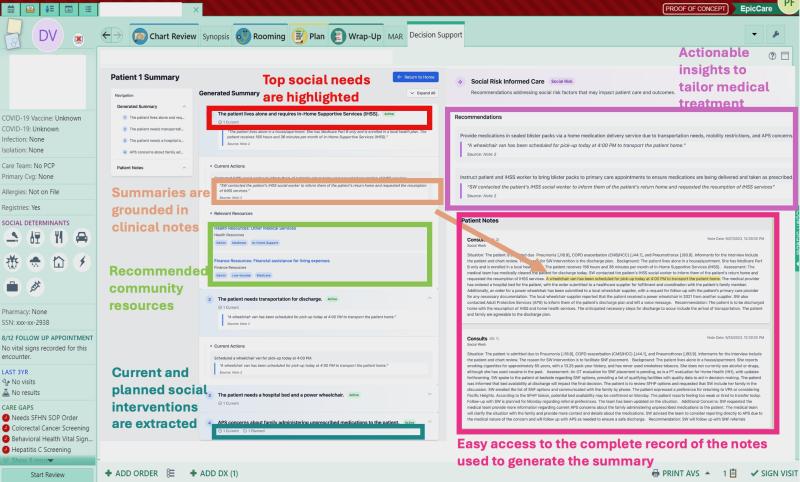
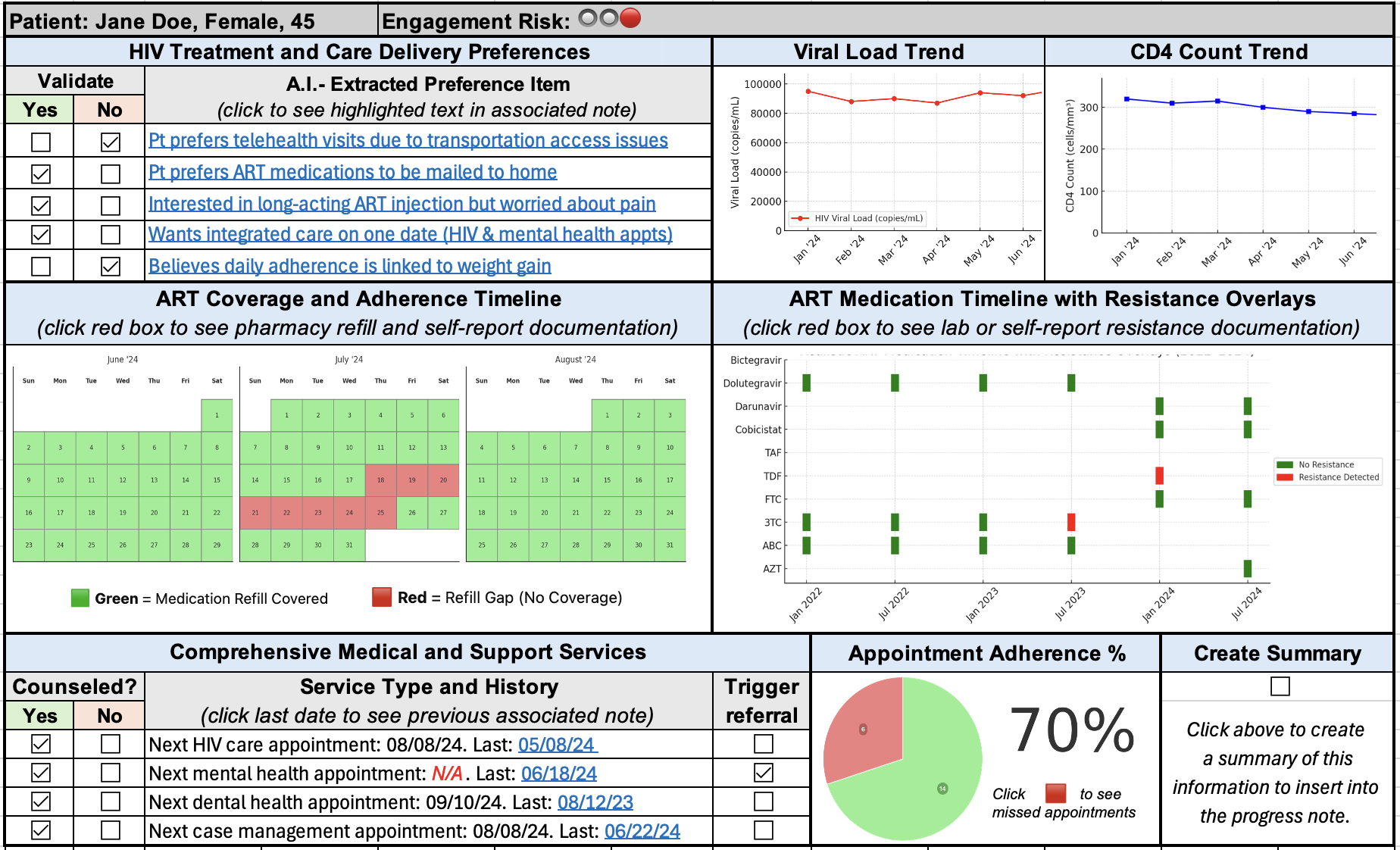
 As an interpretability component of model results to promote clinician oversight, the notification will include a report generated by UCSF Versa GPT, a PHI-secure large language model (Figure 3).The report explains the rationale behind the model’s prediction using LLM-generated descriptions of the most important features for that patient. The surgical and TPS team will review this information and act on its recommendation—specifically, by initiating a referral to the TPS and coordinating perioperative pain management strategies. This low-friction, automated approach ensures the AI support is easily discoverable, actionable, and aligns with existing clinical workflows.
As an interpretability component of model results to promote clinician oversight, the notification will include a report generated by UCSF Versa GPT, a PHI-secure large language model (Figure 3).The report explains the rationale behind the model’s prediction using LLM-generated descriptions of the most important features for that patient. The surgical and TPS team will review this information and act on its recommendation—specifically, by initiating a referral to the TPS and coordinating perioperative pain management strategies. This low-friction, automated approach ensures the AI support is easily discoverable, actionable, and aligns with existing clinical workflows.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}